TweetsKB is a public RDF corpus of anonymized data for a large collection of annotated tweets. The dataset currently contains data for nearly 3.1 billion tweets, spanning more than 10 years until the Twitter API was closed in 06.2023. Metadata information about the tweets as well as extracted entities, sentiments, hashtags and user mentions are exposed in RDF using established RDF/S vocabularies. For the sake of privacy, we encrypt the usernames and we do not provide the text of the tweets. However, the tweet IDs can be used to retrieve the original Tweet text.
More information is available at the following paper:
TweetsCOV19
is a subset of TweetsKB containing COVID-related tweets and reflects
the societal
discourse about COVID-19 on Twitter in the period of October 2019 until April 2020.
•TweetsKB is available as Notation3 (N3) files (split by month) through the Zenodo data repository (under a Creative Commons Attribution 4.0 license) and GESIS Search:
| Dataset Part | Zenodo Link | Entity Linking |
|---|---|---|
| Part 1 (Feb 2013 - Feb 2014) | https://zenodo.org/record/573852 | Yahoo FEL with Wikipedia Dump from November 2015 |
| Part 2 (Mar 2014 - Nov 2014) | https://zenodo.org/record/577572 | Yahoo FEL with Wikipedia Dump from November 2015 |
| Part 3 (Dec 2014 - Dec 2015) | https://zenodo.org/record/579597 | Yahoo FEL with Wikipedia Dump from November 2015 |
| Part 4 (Jan 2016 - Nov 2016) | https://zenodo.org/record/579601 | Yahoo FEL with Wikipedia Dump from November 2015 |
| Part 5 (Dec 2016 - Oct 2017) | https://zenodo.org/record/1095592 | Yahoo FEL with Wikipedia Dump from November 2015 |
| Part 6 (Nov 2017 - Mar 2018) | https://zenodo.org/record/1808741 | Yahoo FEL with Wikipedia Dump from November 2015 |
| Part 7 (Apr 2018 - Apr 2019) | https://zenodo.org/record/3828929 | Yahoo FEL with Wikipedia Dump from April 2020 |
| Part 8 (May 2019 - Apr 2020) | https://zenodo.org/record/3828949 | Yahoo FEL with Wikipedia Dump from April 2020 |
| Part 9 (May 2020 - Dec 2020) | https://zenodo.org/record/4420178 | Yahoo FEL with Wikipedia Dump from April 2020 |
| Part 10 (Jan 2021 - Dec 2021) | https://doi.org/10.7802/2472 | Yahoo FEL with Wikipedia Dump from August 2022 |
| Part 11 (Jan 2022 - Aug 2022) | https://doi.org/10.7802/2473 | Yahoo FEL with Wikipedia Dump from August 2022 |
| Part 12 (Sep 2022 - Jun 2023) | https://doi.org/10.78l02/2781 | Yahoo FEL with Wikipedia Dump from June 2023 |
• SPARQL endpoint containing a 5% sample of the dataset: SPARQL endpoint (Default Graph: http://data.gesis.org/tweetskb)
| Feature | Total | Unique | Ratio of tweets with at least one feature |
|---|---|---|---|
| Hashtags: | 1,161,839,471 | 68,832,205 | 0.19 |
| Mentions: | 1,840,456,543 | 149,277,474 | 0.38 |
| Entities: | 2,563,433,997 | 2,265,201 | 0.56 |
| Non-neutral sentiment: | 1,265,974,641 | - | 0.5 |
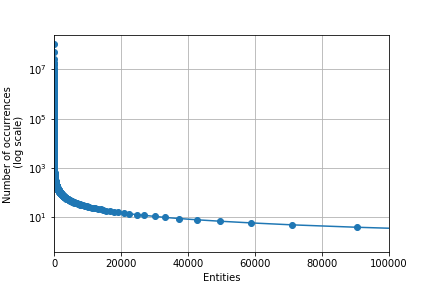
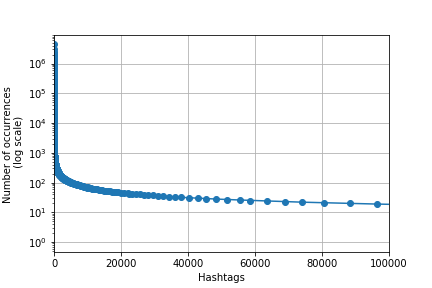
Entities with confidence thresholds -1.
| Entity | Count |
|---|---|
| YouTube | 11,031,812 |
| 5,530,023 | |
| 5,064,670 | |
| Guess_(clothing) | 4,416,317 |
| Harry_Styles | 2,657,646 |
| The_Weather_Channel | 2,499,980 |
| CNN | 2,414,882 |
| 2,129,375 | |
| Netflix | 1,990,180 |
| EBay | 1,973,536 |
| SoundCloud | 1,816,846 |
| Britney_Spears | 1,439,859 |
| Etsy | 1,289,528 |
| Lana_Del_Rey | 1,260,523 |
| 1,207,049 | |
| Blackpink | 1,079,633 |
| Amazon.com | 1,063,110 |
| Not_safe_for_work | 1,048,587 |
| Got7 | 1,039,332 |
| Spotify | 1,035,797 |
Entities with confidence thresholds -2.
| Entity | Count |
|---|---|
| You | 100,902,750 |
| LOL | 34,304,976 |
| YouTube | 14,305,365 |
| 10,657,535 | |
| 9,641,694 | |
| Yahoo!_News | 9,371,001 |
| BTS | 7,429,176 |
| Happy_Birthday_to_You | 7,072,576 |
| World_of_Warcraft | 5,852,425 |
| Young-adult_fiction | 5,795,295 |
| Yo | 4,789,585 |
| The_Weather_Channel | 4,516,875 |
| Guess_(clothing) | 4,416,500 |
| Ask.com | 4,046,042 |
| 5_Seconds_of_Summer | 4,040,199 |
| Primary_lateral_sclerosis | 4,026,400 |
| PPL_Corporation | 3,507,805 |
| LMFAO | 3,354,678 |
| 3,298,283 | |
| Lady_Gaga | 3,245,063 |
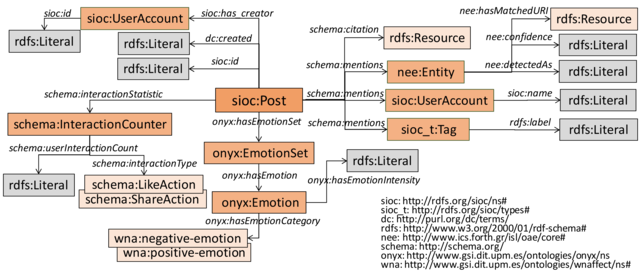
The following figure illustrates the data model and features captured for single tweet instances. Features are extracted from tweets using a pipeline described in the paper listed here. Please note that entity and sentiment annotations may include noise, that is, our pipeline does not achieve perfect precision and recall. For all entity annotations, we provide a confidence score (nee:confidence) which allows you to choose a confidence threshold suitable to your use case, for instance, emphasising either precision or recall.
RDF/S Model:
Instantiation example:
We plan to publish datasets for other subsets.
Team:
- Erdal Baran,
- Stefan
Dietze(GESIS – Leibniz Institute for the Social Sciences and Heinrich-Heine-University Düsseldorf) (main
contact),
- Dimitar Dimitrov,
- Pavlos Fafalios,
- Robert Jäschke,
- Vasileios Iosifidis,
- Ran Yu,
- Xiaofei Zhu,
- Matthäus
Zloch
- Sebastian Schellhammer
- Yudong Zhang
Assert a data protection request: dimitar.dimitrov@gesis.org


The work was partially funded by the European Commission for the ERC Advanced Grant ALEXANDRIA
under grant No. 339233 and
the H2020 Grant No. 687916 (AFEL project).
 >
>
![]()
 Run query
Run query