TweetsCOV19 is a semantically annotated corpus of Tweets about the COVID-19
pandemic. It is a subset
of TweetsKB and aims at
capturing online discourse about various aspects of the pandemic and its societal
impact. Metadata
information about the tweets as well as extracted entities,
sentiments,
hashtags and
user mentions are exposed in RDF using established RDF/S vocabularies.
This dataset consists of 41,307,082 tweets in total, posted by 12,825,911 users and reflects the societal discourse about COVID-19 on Twitter in the period of October 2019 until August 2022. In total, this makes 676,368,018 statements in RDF, which can be queried using the SPARQL-endpoint described below.
More information is available at the following paper:
The TweetsCOV19 dataset reflects online discourse during the COVID-19 pandemic in a pre-processed fashion, following established knowledge graph principles. Thus, TweetsCOV19 represents a unique corpus for studying online discourse during the Corona pandemic together with its societal impact.
On the one hand, the dataset facilitates research in the (computational) social sciences, for instance, about information diffusion processes or the impact of (dis-)information on attitudes, solidarity, risk assessment and public opinion. On the other hand, the data may serve to evaluate and improve computational methods for tasks such as sentiment analysis, event detection, topic analysis or retweet prediction.
To extract the dataset from TweetsKB, we applied a seed list of 268 COVID-19-related keywords. The seed list is an extension of the seed list of Chen et al. and allows a broader view on the societal discourse on COVID-19 on Twitter.
Tweets in TweetsCOV19 contain at least one keyword from the set of seed terms, are written in English and published throughout the aforementioned time period. Data cleaning and enrichment as described in TweetsKB has been applied.
• TweetsCOV19 is available as Notation3 (N3) and tab-separated values (tsv) files through the Zenodo data repository (under a Creative Commons Attribution 4.0 license):
| Dataset Part | Zenodo Link | Entity Linking | Keywords |
|---|---|---|---|
| Part 1 (Oct 2019 - April 2020) | https://zenodo.org/record/3871753 | Yahoo FEL Wikipedia April 2020 Dump | List v1 |
| Part 2 (May 2020 - May 2020) | https://zenodo.org/record/4593502 | Yahoo FEL Wikipedia April 2020 Dump | List v1 |
| Part 3 (June 2020 - Dec 2020) | https://zenodo.org/record/4593524 | Yahoo FEL Wikipedia February 2021 Dump | List v1.1 |
| Part 4 (Jan 2021 - Aug 2022) | https://doi.org/10.7802/2470 | Yahoo FEL Wikipedia August 2022 Dump | List v1.1 |
• SPARQL endpoint containing the full dataset: SPARQL endpoint (Default Graph: http://data.gesis.org/tweetscov19)
• TSV File format Each line contains features of a tweet instance. Features are separated by tab character ("\t"). The following list indicate the feature indices:
| Feature | Total | Unique | Ratio of tweets with at least one feature |
|---|---|---|---|
| Hashtags: | 18,734,035 | 1,775,379 | 0.28 |
| Mentions: | 28,139,872 | 5,124,474 | 0.44 |
| Entities: | 59,378,032 | 700,136 | 0.70 |
| Non-neutral sentiment: | 24,528,721 | - | 0.59 |
|
|
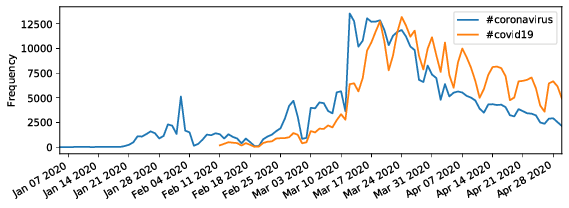
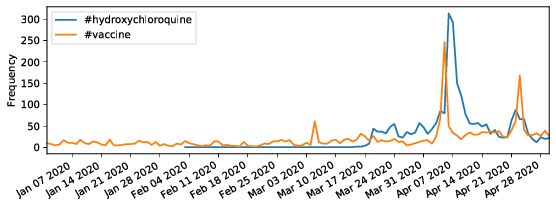
The figure shows a comparison of hashtag popularity over time for (a) the two most popular hashtags #coronavirus and #covid19, and for (b) #hydroxychloroquine vs. #vaccine.
|
|
|
|
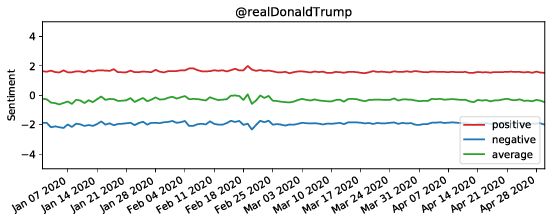
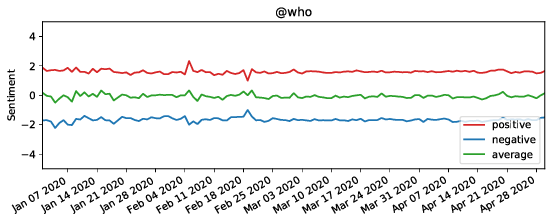
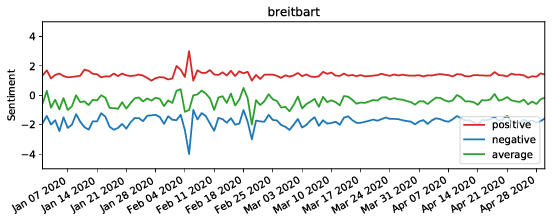
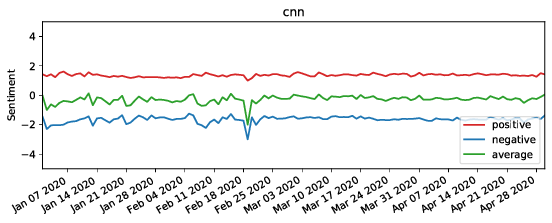
The figure shows the sentiment of tweets mentioning Donald Trump and WHO (the upper two figures), and containing URLs to Breitbart (the lower two figures) - a politically far-right-wing associated news media - and CNN - a left-wing associated media.
The table shows the top five entities (confidence level -2) and their
frequency
per month in the
TweetsCOV19 dataset since the beginning of 2020.
| January 2020 | February 2020 | ||
|---|---|---|---|
| entity | frequency | entity | frequency |
| Wuhan | 10,147 | Wuhan | 10,494 |
| Iran | 5,905 | Coronavirus_disease_2019 | 4,999 |
| BTS | 5,014 | BTS | 4,513 |
| What's_Happening!! | 4,899 | What's_Happening!! | 3,431 |
| 4,105 | 3,351 | ||
| March 2020 | April 2020 | ||
|---|---|---|---|
| entity | frequency | entity | frequency |
| Coronavirus_disease_2019 | 178,396 | Coronavirus_disease_2019 | 200,342 |
| Social_distancing | 66,176 | Social_distancing | 52,323 |
| Italy | 22,164 | India | 18,992 |
| Wuhan | 16,804 | Hydroxychloroquine | 15,820 |
| India | 15,822 | Wuhan | 14,478 |
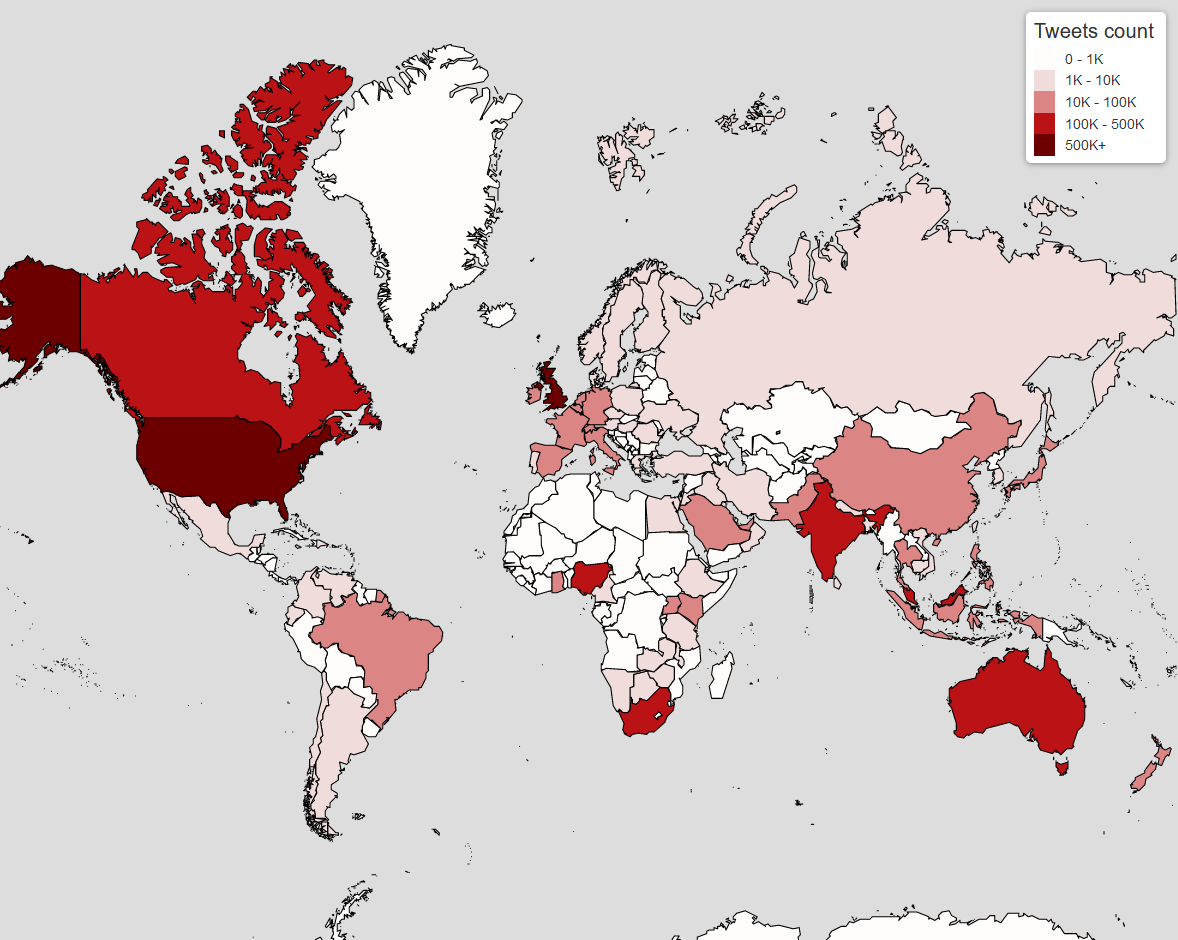
The following map shows the approximated geolocation distribution of TweetsCOV19 tweets at a global scale. We also provide countrly level geolocation for USA, UK, Germany, France, Italy, Spain and India. Maps are created from geotags obtained through the pre-trained DeepGeo neutral network.
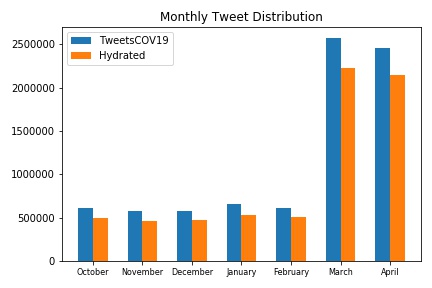
The Figure shows the monthly distribution of TweetsCOV19 tweets before (original dataset) and after hydration. From the 8,151,524 tweets IDs in TweetsCOV19, the hydrator was able to obtain the raw tweet data for 6.856.135 IDs.
The following figure illustrates the data model and features captured for single tweet instances. Features are extracted from tweets using a pipeline described in the paper listed here. Please note that entity and sentiment annotations may include noise, that is, our pipeline does not achieve perfect precision and recall. For all entity annotations, we provide a confidence score (nee:confidence) which allows you to choose a confidence threshold suitable to your use case, for instance, emphasising either precision or recall.
RDF/S Model:
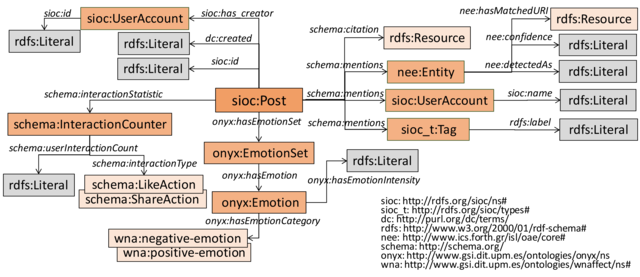
Instantiation example:
To capture COVID-19-related discourse on Twitter, several datasets have been
released for academic use, including one stream API (last entry in
table). We list these here as a reference point for other researchers
interested in using complementary datasets and features. To the best of
our knowledge, TweetsCOV19
and TweetsKB are
the only
publicly available
knowledge bases containing both precomputed entity and sentiment
annotations together with extracted tweet metadata.
| available tweet information | other annotation | dates contained | extraction method | languages | available format | number of tweets | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A large-scale COVID-19 Twitter chatter dataset for open scientific research - an international collaboration | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, date, time | top 1000 frequent terms, bigrams and trigrams | March 11, 2020 - present (smaller proportion January 1, 2020 - March 11th 2020) |
tweets mentioning specific keywords (13 keywords) | all | csv and tsv files | 309,326,736 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tracking Social Media Discourse About the COVID-19 Pandemic: Development of a Public Coronavirus Twitter Data Set | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, date | - | January 21, 2020 - present, updated weekly |
tweets mentioning specific keywords, and tweets from specified accounts | all | txt files | 129,911,732 (v1.9) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Coronavirus (COVID-19) Tweets Dataset | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, time frame | Sentiment score of each tweet | March 20, 2020 - present updated daily |
tweets mentioning specific keywords | English | csv files | 102,650,603 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Coronavirus (COVID-19) Geo-tagged Tweets Dataset | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, longitude, latitude | - | since April 28, 2020, updated daily |
tweets mentioning specific keywords and contains location informaion | all | csv and json files | - | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Coronavirus Twitter Data: A collection of COVID-19 tweets with automated annotations | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, user ID, date | inferred geolocation | February 6, 2020 - May 20, 2020, updated regularly |
tweets mentioning specific keywords (15 keywords) | all | json files | - | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Coronavirus Tweet Ids | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID | - | March 3, 2020 - May 1, 2020 (version 5) |
tweets mentioning specific keywords (3 keywords) | all | txt files | 188,026,475 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GeoCoV19: A Dataset of Hundreds of Millions of Multilingual COVID-19 Tweets with Location Information | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, user ID, tweet location, user location, | place mentioned in tweets | Feb 1, 2020 - May 1, 2020 |
800 hashtags and keywords | multilingual (62) | tsv, json | 524,353,432 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Crowdbreaks: Tracking health trends using public social media data and crowdsourcing | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, location | place mentioned in tweets | January 12, 2020 - May 20, 2020 |
tweets mentioning specific keywords (5 keywords) | English | txt files | - | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Large Arabic Twitter Dataset on COVID-19 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, date | - | January 1 - April 30, 2020 |
tweets mentioning specific keywords, and written in Arabic | Arabic | txt files | 4,514,136 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ArCOV-19: The First Arabic COVID-19 Twitter Dataset with Propagation Networks | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, date | - | January 27, 2020 - March 31, 2020 |
tweets written in Arabic and returned by Twitter Standard search API when using COVID related keywords (e.g. Corona) as queries | Arabic | plain text file | 747,599 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| NAIST COVID: Multilingual COVID-19 Twitter and Weibo Dataset | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID/micro blog ID, user ID, date | - | January 20, 2020 - March 24, 2020 |
filtering based on combination (AND, OR) of keywords and language | English, Japanese. Chinese (from Weibo) | tsv files | 16,250,038 in English, 9,501,866 in Japanese, 173,869 in Chinese | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Corona Virus (COVID-19) Turkish Tweets Dataset | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tweet ID, time, user ID To-User-Id(if it is sent to a user), number of retweets |
- | March 9, 2020 - May 6, 2020 |
tweets mentioning specific keywords (4 keywords) and written in Turkish | Turkish | csv files | 4.8 million | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| COVID-19 stream | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Full tweet objects | - | real-time | tweets mentioning specific keywords (590 hashtags and keywords by 13 May 2020) | all | streaming endpoint | - | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Team:
- Erdal Baran,
- Stefan
Dietze(GESIS – Leibniz Institute for the Social Sciences and Heinrich-Heine-University Düsseldorf) (main contact),
- Dennis Segeth
- Dimitar
Dimitrov,
- Pavlos
Fafalios,
- Robert
Jäschke,
- Ran Yu,
- Xiaofei Zhu,
- Matthäus
Zloch
- Yudong Zhang
Assert a data protection request: dimitar.dimitrov@gesis.org


 Run query
Run query