Following figure illustrates the annotations’ structure of SoMeSci on an example sentence containing a
mention of the software “R”.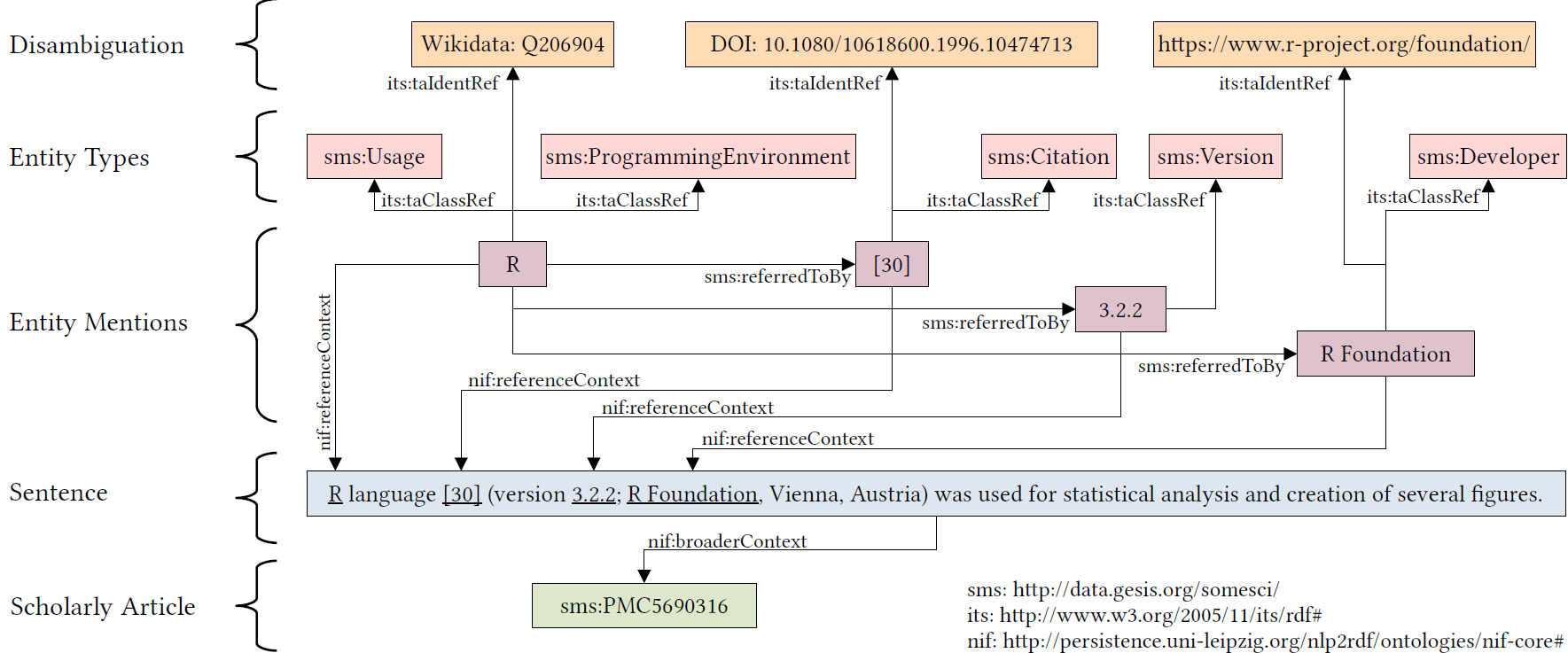
Knowledge about software used in scientific investigations is important for several reasons, for instance, to enable an understanding of provenance and methods involved in data handling. However, software is usually not formally cited, but rather mentioned informally within the scholarly description of the investigation, raising the need for automatic information extraction and disambiguation. Given the lack of reliable ground truth data, we present SoMeSci - Software Mentions in Science - a gold standard knowledge graph of software mentions in scientific articles. It contains high quality annotations (IRR: κ = .82) of 3756 software mentions in 1367 PubMed Central articles. Besides the plain mention of the software, we also provide relation labels for additional information, such as the version, the developer, a URL or citations. Moreover, we distinguish between different types, such as application, plugin or programming environment, as well as different types of mentions, such as usage or creation. To the best of our knowledge, SoMeSci is the most comprehensive corpus about software mentions in scientific articles, providing training samples for Named Entity Recognition, Relation Extraction, Entity Disambiguation, and Entity Linking. Finally, we sketch potential use cases and provide baseline results for the different tasks.
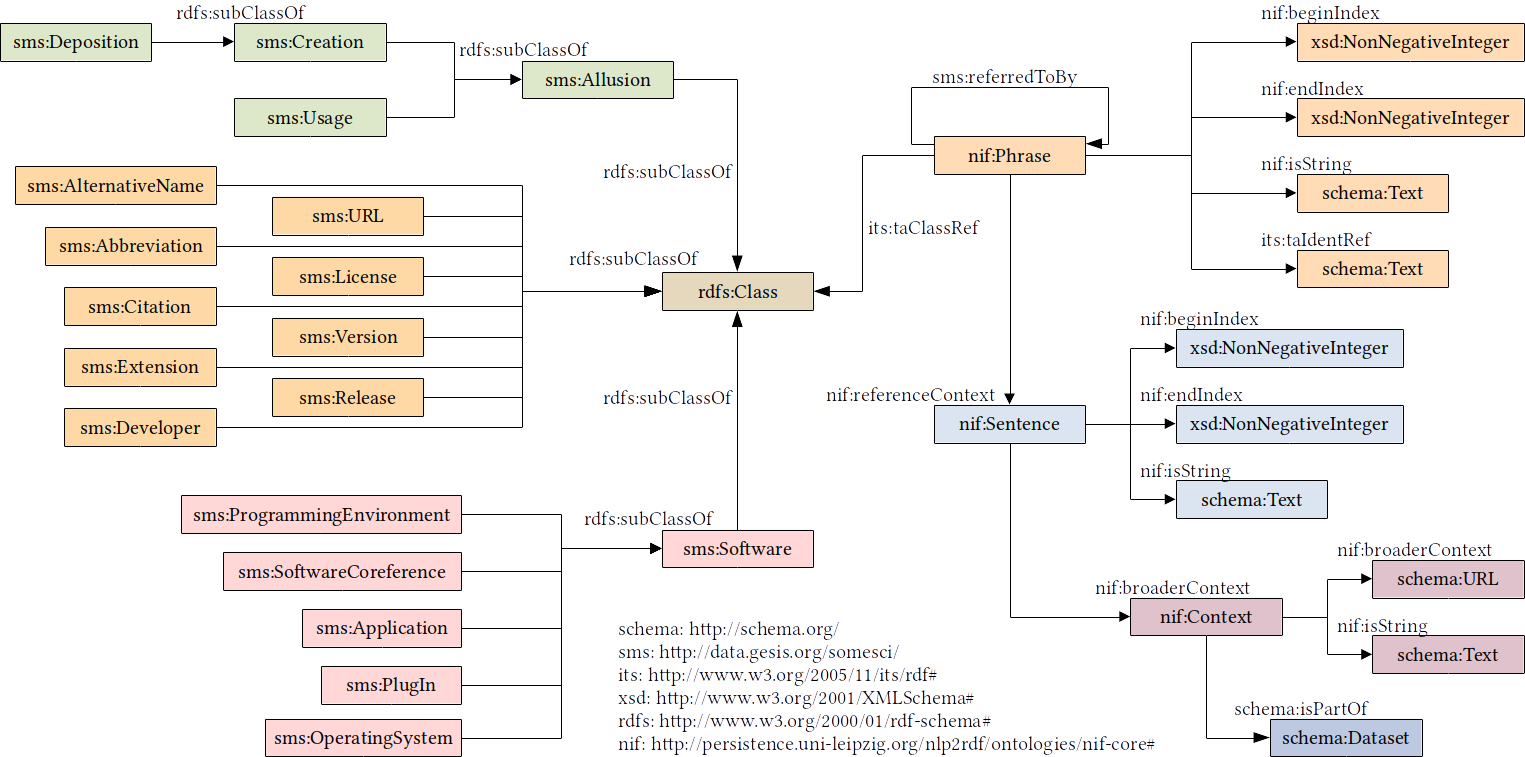
The figure below displays the data model of SoMeSci.
| Feature | Value |
|---|---|
| Triples | 399,942 |
| Resources | 56,168 |
| Distinct types | 8 |
| Distinct properties | 45 |
| Documents in “Creation Sentences” | 110 |
| Documents in “PLoS methods” | 480 |
| Documents in “PLoS sentences” | 677 |
| Documents in “Pubmed fulltexts” | 100 |
| Sentences | 47,524 |
| Entity mentions | 7,237 |
| Versions | 1,381 |
| Developers | 858 |
| Citations | 588 |
| URLs | 347 |
| Releases | 87 |
| Abbreviations | 81 |
| Licenses | 53 |
| Alternative names | 35 |
The latest release of SoMeSci can be downloaded at https://zenodo.org/record/4701763.
A SPARQL endpoint is available to send SPARQL queries and retrieve results from the SoMeSci knowledge graph.
https://data.gesis.org/somesci/sparql
Graph URL: http://data.gesis.org/somesci
Example 1: Requesting dataset metadata. (Result)
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT ?p ?o ?p2 ?o2
WHERE{
<http://data.gesis.org/somesci/> ?p ?o .
OPTIONAL{
?s dcterms:creator ?o .
?o ?p2 ?o2
}
}
ORDER BY ?p ?o ?p2 ?o2Example 2: Requesting the number of documents per dataset. (Result)
PREFIX nif: <http://persistence.uni-leipzig.org/nlp2rdf/ontologies/nif-core#>
PREFIX void: <http://rdfs.org/ns/void#>
PREFIX dcterms: <http://purl.org/dc/terms/>
PREFIX schema: <http://schema.org/>
SELECT ?datasetName (COUNT(?document) AS ?no_documents )
WHERE{
?document a nif:Context .
?document schema:isPartOf ?dataset .
?dataset dcterms:title ?datasetName .
}
GROUP BY ?datasetName
ORDER BY ?datasetNameExample 3: Requesting the top 10 of most mentioned software. (Result)
PREFIX nif: <http://persistence.uni-leipzig.org/nlp2rdf/ontologies/nif-core#>
PREFIX sms: <http://data.gesis.org/somesci/>
PREFIX its: <http://www.w3.org/2005/11/its/rdf#>
SELECT ?sw_identity (COUNT(?sw_identity) AS ?no_mentions)
WHERE{
?sw_phrase a nif:Phrase .
?sw_phrase its:taClassRef [rdfs:subClassOf sms:Software] .
?sw_phrase its:taIdentRef ?sw_identity .
}
ORDER BY DESC (?no_mentions) ?sw_identity
LIMIT 10Example 4: Requesting spelling variations and alternative names of software. (Result)
PREFIX nif: <http://persistence.uni-leipzig.org/nlp2rdf/ontologies/nif-core#>
PREFIX sms: <http://data.gesis.org/somesci/>
PREFIX its: <http://www.w3.org/2005/11/its/rdf#>
SELECT ?sw_identity (COUNT(DISTINCT ?spelling) AS ?no_spellings) (GROUP_CONCAT(DISTINCT ?spelling; SEPARATOR=", ") AS ?spelling_variations) (GROUP_CONCAT(DISTINCT ?alt_name; SEPARATOR=", ") AS ?alternative_names)
WHERE{
?sw_phrase a nif:Phrase .
?sw_phrase its:taClassRef [ rdfs:subClassOf sms:Software ] .
?sw_phrase its:taIdentRef ?sw_identity .
?sw_phrase nif:anchorOf ?spelling .
OPTIONAL{
?sw_phrase sms:referredToBy ?alt_name_mention .
?alt_name_mention its:taClassRef [ rdfs:subClassOf sms:Software ] .
?alt_name_mention nif:anchorOf ?alt_name.
}
}
GROUP BY ?sw_identity
ORDER BY DESC(?no_spellings) ?sw_identityExample 5: Requesting citation completeness. (Result)
PREFIX nif: <http://persistence.uni-leipzig.org/nlp2rdf/ontologies/nif-core#>
PREFIX sms: <http://data.gesis.org/somesci/>
PREFIX its: <http://www.w3.org/2005/11/its/rdf#>
SELECT ?sw_type (COUNT(?sw_type) AS ?total) (COUNT(?version_phrase) AS ?no_versions) (COUNT(?url_phrase) AS ?no_urls) (COUNT(?citation_phrase) AS ?no_citations) (COUNT(?release_phrase) AS ?no_releases)
WHERE{
?sw_phrase its:taClassRef ?sw_type .
OPTIONAL{
?sw_phrase sms:referredToByVersion ?version_phrase .
?version_phrase its:taClassRef sms:Version
}
OPTIONAL{
?sw_phrase sms:referredToByURL ?url_phrase .
?url_phrase its:taClassRef sms:URL
}
OPTIONAL{
?sw_phrase sms:referredToByCitation ?citation_phrase.
?citation_phrase its:taClassRef sms:Citation
}
OPTIONAL{
?sw_phrase sms:referredToByRelease ?release_phrase .
?release_phrase its:taClassRef sms:Release
}
VALUES ?sw_type {sms:ProgrammingEnvironment sms:Application sms:OperatingSystem sms:PlugIn }
}
GROUP BY ?sw_type
ORDER BY ?sw_typeExample 6: Requesting co-applied software. (Result)
PREFIX nif: <http://persistence.uni-leipzig.org/nlp2rdf/ontologies/nif-core#>
PREFIX sms: <http://data.gesis.org/somesci/>
PREFIX its: <http://www.w3.org/2005/11/its/rdf#>
SELECT (?ident_a AS ?sw) (GROUP_CONCAT(DISTINCT ?spelling_b; SEPARATOR=", " ) AS ?cooccurring_sw)
WHERE{
?sw_phrase_a a nif:Phrase .
?sw_phrase_a its:taClassRef [rdfs:subClassOf sms:Software] .
?sw_phrase_a its:taIdentRef ?ident_a .
?sw_phrase_a nif:referenceContext [nif:broaderContext ?common_broader_context] .
?sw_phrase_a nif:anchorOf ?spelling_a .
?sw_phrase_b a nif:Phrase .
?sw_phrase_b its:taClassRef [rdfs:subClassOf sms:Software] .
?sw_phrase_b its:taIdentRef ?ident_b .
?sw_phrase_b nif:referenceContext [nif:broaderContext ?common_broader_context] .
?sw_phrase_b nif:anchorOf ?spelling_b .
FILTER( STRLEN (?spelling_b) < 25 )
FILTER(?ident_a != ?ident_b)
}
GROUP BY ?ident_a
ORDER BY ?ident_aExample 7: Requesting number of sentences by number of annotations. (Result)
PREFIX nif: <http://persistence.uni-leipzig.org/nlp2rdf/ontologies/nif-core#>
PREFIX its: <http://www.w3.org/2005/11/its/rdf#>
SELECT ?no_labels (COUNT(?sentence) AS ?no_sentences)
WHERE{
SELECT ?sentence (COUNT(?annotation_phrase) AS ?no_labels)
WHERE{
?sentence a nif:Sentence .
OPTIONAL{
?annotation_phrase nif:referenceContext ?sentence .
}
}
GROUP BY ?sentence
}
GROUP BY ?no_labels
ORDER BY ?no_labelsThe source code of all components of SoMeSci is available on GitHub at https://github.com/dave-s477/SoMeSci_Code.
The dataset is published under a Creative Commons Attribution 4.0 license.
David Schindler, Felix Bensmann, Stefan Dietze, and Frank Krüger. 2021. SoMeSci - A 5 Star Open Data Gold Standard Knowledge Graph of Software Mentions in Scientific Articles. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (CIKM ‘21). Association for Computing Machinery, New York, NY, USA, 4574–4583. DOI: https://doi.org/10.1145/3459637.3482017
Please provide your feedback and any comments by sending an email to somesci (at) gesis (dot) org .